
di Albenzio Cirillo, Ricercatore FUB
Il termine “sovranità digitale” potrebbe erroneamente richiamare concetti di sovranità che sono appannaggio di una teoria economica che persegue i principi autarchici, mentre nel contesto digitale l’uso indica come obiettivo il pieno raggiungimento della capacità di esercitare un controllo effettivo sulle proprie risorse tecnologiche. La crucialità di questo aspetto deriva dal fatto che, quando la tecnologia è utilizzata in un processo decisionale, bisogna considerare che ogni elemento della catena tecnologica è un fattore che influenza il risultato. Di conseguenza non dovrebbero esserci componenti non trasparenti o non governabili dalle persone fisiche che supervisionano il processo decisionale.
Il processo di trasformazione digitale che interessa l’Europa e l’Italia ha subito nell’ultimo periodo una profonda accelerazione con la diffusione dell’intelligenza artificiale generativa. Tuttavia, è evidente come questo processo sia condizionato dalla dipendenza critica da infrastrutture e modelli governati da soggetti extra-UE. La quasi totalità del mercato cloud e dei grandi modelli di AI è oggi nelle mani di pochi hyperscaler, una condizione che crea vulnerabilità non solo economiche, ma anche geopolitiche. Ne consegue che affidare i dati sensibili della Pubblica Amministrazione o i segreti industriali a “scatole nere” gestite in giurisdizioni estere espone il Paese a rischi di lock-in tecnologico e a potenziali accessi extragiudiziali ai dati, pericolo concretizzatosi con l’emanazione del CLOUD Act (Clarifying Lawful Overseas Use of Data Act) negli Stati Uniti.
Oltre agli aspetti strategici menzionati, bisogna considerare un aspetto non banale legato ai processi conoscitivi: i Large Language Model (LLM) stanno sostituendo in maniera diffusa i motori di ricerca classici, grazie alla capacità di fornire dei contenuti esaustivi e più facilmente “digeribili”, per cui reputati affidabili. Al di là del rischio allucinazioni – generazione di risposte plausibili ma false, e inventate dall’AI – l’uso esclusivo di modelli esteri comporta l’importazione di bias culturali e valoriali intrinseci ai dati su cui sono stati addestrati (spesso anglo-centrici). Questo fenomeno genera un “rischio epistemico”: l’AI potrebbe interpretare la realtà, la storia o le norme sociali in modo divergente rispetto alla sensibilità nazionale ed europea. Anche per questo si fa pressante l’urgenza di sviluppare alternative per evitare tale influenza cognitiva. Anche in questo senso, il controllo della tecnologia e dei dati è un requisito non più procrastinabile.
I pilastri del controllo della sovranità sull’AI
Per quanto l’AI ACT abbia costituito una pietra miliare nella normazione relativa all’IA, esso si focalizza prettamente sulla regolamentazione dell’uso dell’intelligenza artificiale, individuando perfettamente i diritti degli utilizzatori e gli aspetti di sicurezza, ma non definisce i parametri per la realizzazione di una AI sovrana. Garantire che un algoritmo sia spiegabile (la capacità dei sistemi AI di fornire spiegazioni chiare e comprensibili riguardo alle loro azioni e decisioni) e addestrato su dati “puliti” rende l’AI più sicura, la quale tuttavia si affida ad algoritmi controllati da soggetti terzi realizzati con codice chiuso. La vera sovranità richiede che la spiegabilità derivi dal possesso del modello e che la qualità del dato sia garantita dalla residenza infrastrutturale.
Pertanto, è necessario possedere e governare i fattori chiave che permettono il funzionamento dell’AI. Possiamo individuare tre pilastri fondamentali su cui si regge la sovranità tecnologica.
- Infrastruttura fisica e residenza del dato: Il primo livello riguarda il controllo dei chip e dei data center. È fondamentale garantire che l’infrastruttura di calcolo, ovvero quella su cui girano i modelli di inferenza, risieda fisicamente sul territorio nazionale o europeo, assicurando la cosiddetta Data Residency. Questo non solo per ragioni di latenza o efficienza, ma per garantire che i dati siano protetti dallo scudo giuridico europeo (GDPR) e sottratti a normative estere spesso invasive.
- Dati e algoritmi: Il secondo pilastro riguarda la materia prima (i dati) e il motore (l’algoritmo). La sovranità implica la proprietà indiscussa dei dataset di addestramento e la trasparenza del funzionamento algoritmico. Va superata l’opacità delle attuali “black box”, pretendendo di sapere come un modello prende decisioni, su quali dati ha imparato e qual è il flusso attraverso il quale sono stati forniti tali dati.
- Governance e sicurezza: Il terzo pilastro è rappresentato dalle regole e dai meccanismi di difesa. L’AI Act già copre questi aspetti. Tuttavia, bisogna ribadire che quanto previsto a livello normativo introduce una sicurezza a livello procedurale che non si traduce in una capacità di controllo. Volendo portare un esempio, supponiamo la presenza di un supervisore umano (Human-in-the-Loop) in un processo AI ad alto rischio, così come previsto dall’art. 14 dell’AI Act. Il supervisore può esprimere una preferenza come controllo di validità dell’output, applicando il regolamento europeo, ma il conseguente cambio della politica del modello di AI, cioè l’apprendimento della scelta del supervisore, è attuato da chi gestisce l’inferenza del modello, potenzialmente un soggetto terzo che opera in modalità black box. La sicurezza procedurale non si traduce necessariamente in governance operativa, in assenza dell’accesso all’algoritmo e ai dati.
Anche a livello di robustezza, il regolamento europeo rende implicita l’adozione di misure di cybersicurezza contro attacchi come il Data Poisoning (l’avvelenamento dei dati di training) o gli Adversarial Attacks (manipolazioni impercettibili degli input per ingannare l’AI). Tuttavia, il mancato controllo delle infrastrutture che operano gli algoritmi e gestiscono i dati non mette al riparo dal rischio di accesso ai dati o interruzione del servizio per volere delle giurisdizioni competenti su tali infrastrutture.
Il tortuoso percorso verso una sovranità algoritmica
Secondo il “2025 AI Index report” redatto dallo Stanford HAI, nel 2024, le istituzioni con sede negli Stati Uniti hanno prodotto 40 modelli di AI notevoli (che hanno conseguito il superamento dello stato dell’arte e hanno avuto rilevanza commerciale e sociale), rispetto ai 15 della Cina e ai 3 dell’Europa (Mistral AI). Lo stesso report specifica che l’adozione dell’AI generativa nelle aziende europee è al 73%, in linea con Cina e Stati Uniti. Il gap tecnologico risulta evidente e un suo possibile recupero è subordinato a profondi cambiamenti strategici su ciascuno dei pilastri.
Tralasciando la parte infrastrutturale e concentrandosi sulla parte dei dati, le strade da percorrere possono prevedere diverse strategie inerenti alla costruzione di modelli locali.
La risposta al divario tecnologico risiede nello sviluppo di Large Language Models (LLM) “nativi”, addestrati fin dall’inizio su corpus di dati europei di alta qualità. Questi modelli devono essere rispettosi del multilinguismo (tutelando anche le lingue meno diffuse) e conformi by design alle normative UE. Solo possedendo modelli addestrati sulle nostre leggi e nella nostra lingua è possibile garantire un supporto efficace alla Pubblica Amministrazione e alla giustizia.
Tuttavia, la convinzione che un foundation model, con diversi miliardi di parametri, sia necessario per eseguire efficientemente i task più disparati è un concetto messo in discussione dagli studi negli ultimi anni. L’articolo “Textbooks Are All You Need”, pubblicato dalla Microsoft Research nel 2023, ha dimostrato che modelli più piccoli, addestrati con dati di qualità e specializzati, possono competere, se non superare, i modelli fondativi su compiti verticali e specifici. I vantaggi di modelli più piccoli sono legati alla capacità computazionale ridotta e a un maggior controllo dei dati utilizzati per l’addestramento.
Gli Small Language Models (SLM) sono modelli linguistici di dimensioni ridotte progettati per offrire elevate prestazioni con un numero di parametri significativamente inferiore rispetto ai grandi modelli di frontiera. Questi sistemi rappresentano una svolta verso l’efficienza algoritmica, poiché permettono di raggiungere risultati complessi utilizzando meno dati e riducendo drasticamente i costi di addestramento. La compattezza del numero di parametri permette di gestire il calcolo di inferenza anche su infrastrutture locali e per tale motivo si arriva a parlare di Edge AI, ossia intelligenza artificiale eseguita direttamente su dispositivi locali o mobili, anziché su server cloud remoti. Questa tecnologia è progettata per ottimizzare la velocità di calcolo (inferenza) e l’efficienza energetica, risultando ideale per scenari in cui la rapidità di risposta è una priorità assoluta.
Queste caratteristiche determinano una riduzione dei costi e una maggiore accessibilità alle aziende che desiderano integrare l’intelligenza artificiale nelle proprie attività. Ma non è solo questo il punto: lo spostamento della parte computazionale dell’AI verso l’edge è un aspetto che va di pari passo con il concetto di sovranità, che si realizza non solo con l’uso di infrastrutture locali ma anche con un controllo approfondito dei dati utilizzati.
La risposta europea: i progetti IPCEI
L’Europa non è rimasta a guardare. Per colmare il divario tecnologico e industriale, l’Unione ha attivato gli IPCEI (Important Projects of Common European Interest), strumenti strategici che permettono agli Stati membri di finanziare grandi progetti industriali transfrontalieri in deroga parziale alle norme sugli aiuti di stato. In Italia, il fondo IPCEI è istituito presso il Ministero delle Imprese e Made in Italy (MIMIT), che cura le procedure di selezione nazionale. Con riferimento ai pilastri della sovranità digitale AI sono stati attivati tre IPCEI.
- IPCEI CIS (Cloud Infrastructure and Services): Questo progetto mira a rivoluzionare l’infrastruttura dati. L’obiettivo è creare un continuum Cloud-Edge decentralizzato e interoperabile. Invece di avere pochi mega-datacenter centralizzati, l’Europa punta su una rete diffusa (Edge) che elabora i dati vicino a dove vengono generati, garantendo sovranità e bassa latenza.
- IPCEI CIC (Compute Infrastructure Continuum): Complementare al CIS, questo IPCEI mira alla creazione di un’infrastruttura di calcolo per l’intelligenza artificiale che sia sovrana ed europea, basata su un’architettura multi-provider. L’idea è quella di evitare che l’addestramento dei modelli europei debba dipendere dall’affitto di GPU americane, costruendo una capacità di supercalcolo autonoma.
- IPCEI AI (Artificial Intelligence): È l’IPCEI dedicato specificamente all’AI (le cui domande potranno essere presentate al MIMIT fino al 30 gennaio 2026) copre l’intera catena del valore. Il focus è sugli investimenti per creare una filiera industriale completa, dallo sviluppo di processori e sensori innovativi (Low Power Processors) fino alle applicazioni software per l’industria e la sanità, riducendo significativamente il gap tecnologico con i competitor globali.
Architetture per l’autonomia digitale: soluzioni ibride e decentralizzate
Appare inevitabile che l’AI venga utilizzata in maniera diffusa anche nell’arco di tempo che sarà necessario per raggiungere gli obiettivi di autonomia precedentemente affrontati. L’unica via per mitigare il controllo esterno senza frenare l’innovazione risiede in una sovranità by design: implementare architetture che disaccoppino la potenza di calcolo dalla proprietà della conoscenza, riportando il controllo dell’inferenza e dei dati critici all’interno del perimetro nazionale attraverso modelli ibridi e distribuiti.
Il cloud Ibrido come standard: Si tratta della soluzione più pragmatica, la cui architettura permette di integrare il Private Cloud (o le infrastrutture on-premise), dove vengono custoditi i dati sensibili e strategici, utilizzato per attingere a potenza di calcolo scalabile quando necessario. In questo modo si garantisce la scalabilità senza perdere la sovranità sui dati critici.
RAG (Retrieval-Augmented Generation): È una delle tecniche più promettenti per l’uso sicuro dell’AI, con cui disaccoppiamo la “conoscenza” (i dati) dal modello. Usiamo l’AI generativa solo come motore di ragionamento linguistico, ma la obblighiamo a consultare database proprietari sicuri e verificati per trovare le informazioni, invece di affidarsi alla sua memoria di addestramento pubblica (che ovviamente è stata costruita dal fornitore del modello AI e sulla quale un utente non ha controllo). Questo riduce le allucinazioni e garantisce che i dati aziendali o della PA non vengano mai assorbiti dal modello pubblico.
FL (Federated Learning): Infine, per contesti in cui la riservatezza è un requisito essenziale (come la sanità), la soluzione è il Federated Learning. Questa tecnica inverte il paradigma tradizionale: invece di portare tutti i dati in un unico server centrale per l’addestramento (con i conseguenti rischi per la privacy), si “porta l’algoritmo ai dati”. I modelli imparano localmente sui server (edge) degli ospedali o delle pubbliche amministrazioni e condividono con il centro solo i miglioramenti matematici appresi (i pesi), senza che i dati grezzi e sensibili lascino mai il perimetro locale. Inoltre, questa tecnica permette di trasferire una quantità esigua di informazione in rete (solamente i pesi anziché i dati originali come immagini, video, documenti, eccetera), con modeste richieste di uplink tra edge e server centrale. Il FL rimane comunque una soluzione di frontiera, spesso indicata per contesti in cui i vari edge trattano informazioni con caratteristiche statistiche simili (Independent and Identically Distributed – IID). Ad oggi è oggetto di ricerca, per renderlo applicabile in maniera robusta anche ai casi in cui i server locali usano dati eterogenei per l’addestramento.
Il ruolo della Fondazione Ugo Bordoni
In questo scenario complesso, per progettare soluzioni di Intelligenza Artificiale per la Pubblica Amministrazione (PA) è necessario avvalersi di un profilo multidisciplinare che vada oltre la semplice competenza tecnica di sviluppo software. Grazie al suo ruolo strategico a fianco delle istituzioni – come dimostrato dal supporto tecnico al MIMIT per gli IPCEI e dagli obiettivi strategici del Piano Strategico Triennale FUB 2026-2028 – la FUB possiede una visione privilegiata. La Fondazione coniuga la consapevolezza dei rischi geopolitici e di sicurezza con competenze verticali su architetture sovereign-by-design, modelli algoritmici avanzati e programmi di attuazione industriale.
Il ruolo della Fondazione è quello di supportare la pubblica amministrazione per una digitalizzazione responsabile, dove il miglioramento dei servizi a cittadini e imprese sia sostenuto da una infrastruttura costruita secondo i paradigmi di sicurezza e indipendenza tecnologica.
Nel prossimo triennio, la FUB supporterà lo sviluppo di un’IA sovrana integrando il presidio dell’evoluzione tecnologica e regolatoria con la promozione di una transizione sicura sul cloud-edge continuum, fornendo così alle istituzioni gli strumenti necessari per rafforzare la governance, l’innovazione e la sicurezza del dato strategico nazionale.
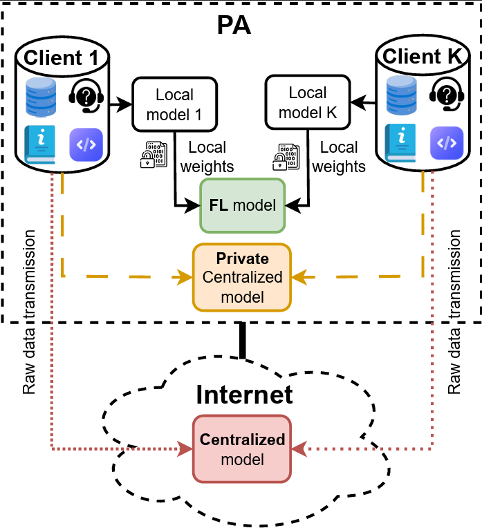
Architetture a confronto: a differenza dei modelli basati sulla centralizzazione dei dati (esterna o interna), il Federated Learning assicura la sovranità condividendo solo i pesi dell’algoritmo e mai i dati sensibili